watch this for a quick intro!
Quickstart
See QUICK_START.md in the codebase for the full guide.
import torch
from autogaze.datasets.video_utils import transform_video_for_pytorch
from autogaze.models.autogaze import AutoGazeImageProcessor, AutoGaze
autogaze_transform = AutoGazeImageProcessor.from_pretrained("bfshi/AutoGaze")
autogaze_model = AutoGaze.from_pretrained("bfshi/AutoGaze")
# ...prepare video input...
video_input_autogaze = transform_video_for_pytorch(raw_video, autogaze_transform)[None]
with torch.inference_mode():
gaze_outputs = autogaze_model({"video": video_input_autogaze},
gazing_ratio=0.75,
task_loss_requirement=0.7)
Introduction
When observing a moving scene, humans don't process every detail equally. Our eyes dart around to moving objects, capture fine details, and skip over static backgrounds, efficiently understanding scenes by selectively attending to informative regions. This allows us to process high-FPS, high-resolution video streams in real time.
In contrast, modern video understanding models still process every pixel in every frame equally, wasting computation due to spatiotemporal redundancy in videos. Thus, these models cannot scale to long-form and high-resolution videos crucial for real-world applications due to computational cost.
We propose AutoGaze, a lightweight model that attends to informative patches and removes redundant ones before passing into a ViT or MLLM. AutoGaze perceives each frame and autoregressively selects a minimal set of multi-scale patches which, along with the selected patches from previous frames, can reconstruct the current frame.
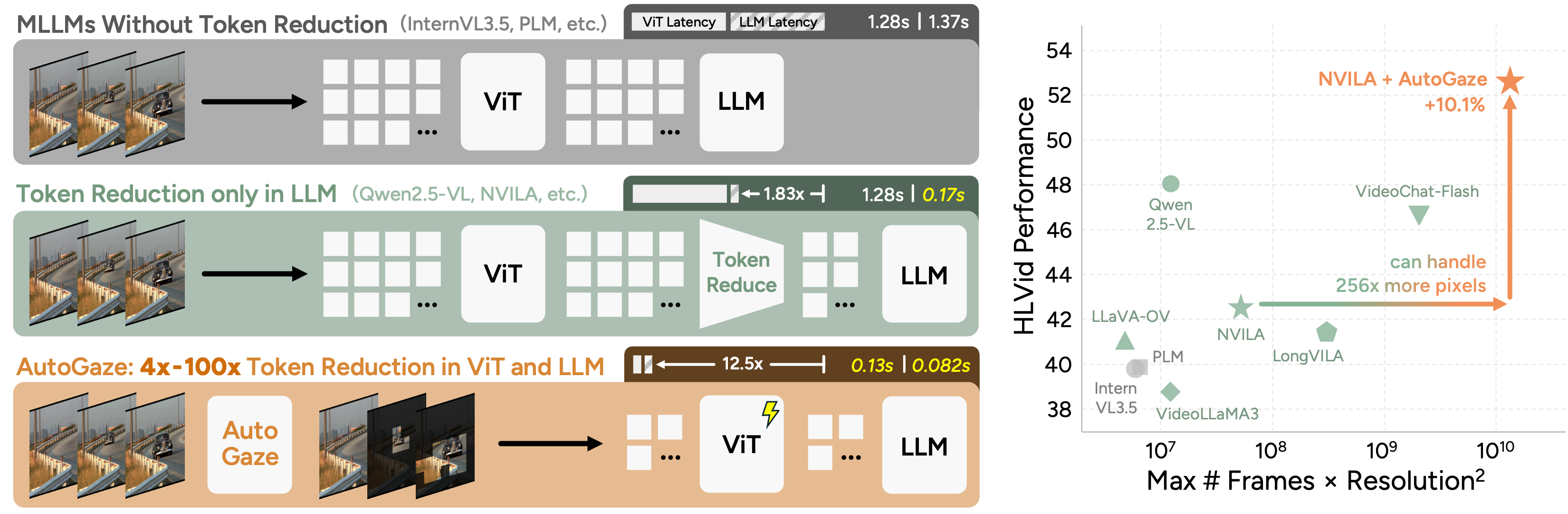
Left: Existing MLLMs either process all pixels which is inefficient, or prune tokens only in their LLMs, leaving ViTs the computational bottleneck. In contrast, AutoGaze eliminates redundant patches by up to 100× before ViTs, accelerating ViTs and MLLMs by up to 19×.
Right: This efficiency enables MLLMs with AutoGaze to scale to 1K-frame, 4K-resolution videos and achieve superior performance on HLVid, our new long, high-resolution video benchmark, surpassing prior MLLMs limited to short or low-resolution videos.
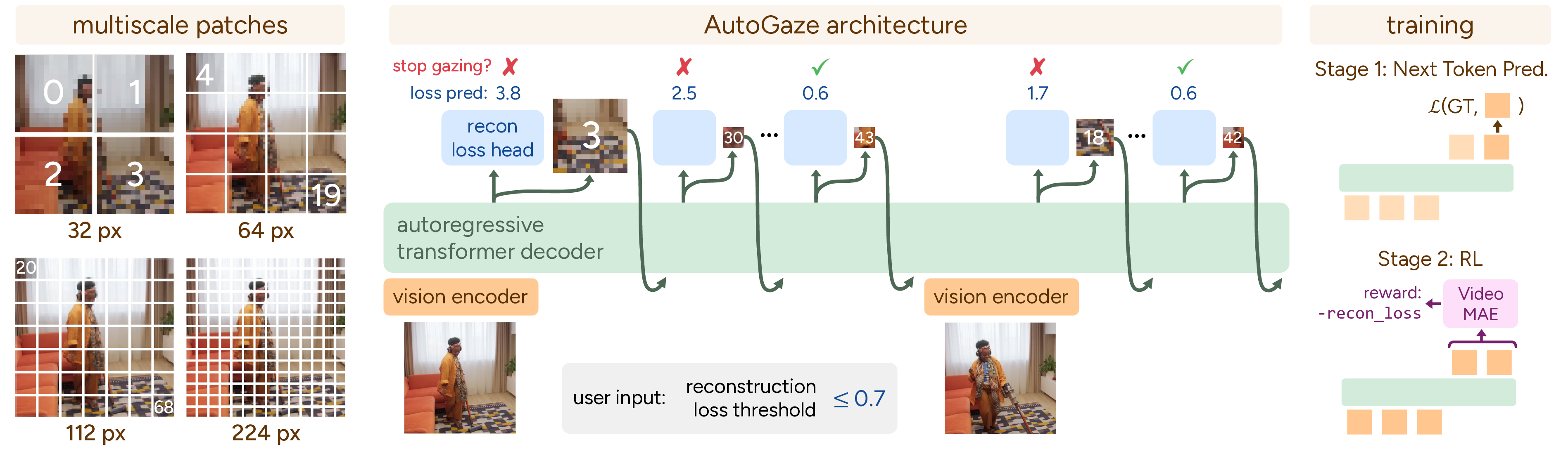
Architecture and Training
Given an input video, AutoGaze selects a minimal set of patches which reconstructs the video within some user-specified reconstruction loss threshold or patch budget.
The model is made up of a convolutional encoder and autoregressive transformer decoder, totaling 3M parameters. The decoder's vocabulary includes patches from four scales, letting it select different scales for regions with different levels of detail and reducing patches while preserving reconstruction quality.
AutoGaze is trained in two stages: we first pre-train with next-token prediction (NTP) on ground-truth gazing sequences, then further post-train AutoGaze using RL with reconstruction reward to discover gazing sequences with lower reconstruction loss.
Qualitative Results
For each example below, we show the original video, gazed patches from two scales, and reconstructed video.
In general, AutoGaze can 1) focus on moving objects while removing redundancy in static regions, 2) adapt to scene changes by selecting more patches, and 3) use different scales based on level of detail. This allows AutoGaze to select a small ratio of patches (gazing ratio) without much information loss, as reflected by the reconstruction quality.
Generalization to Out-of-Distribution Videos
AutoGaze successfully generalizes to unconventional scenarios including CCTV footage, robot videos, and videos with constantly swapping foreground objects.
Generalization to Videos with Camera Motion
AutoGaze also generalizes to videos with camera motion. Although the gazing pattern is less intuitive due to the global motion,
the gazing ratio remains similar and the reconstruction quality is still high.
Efficiency of ViTs and MLLMs with AutoGaze
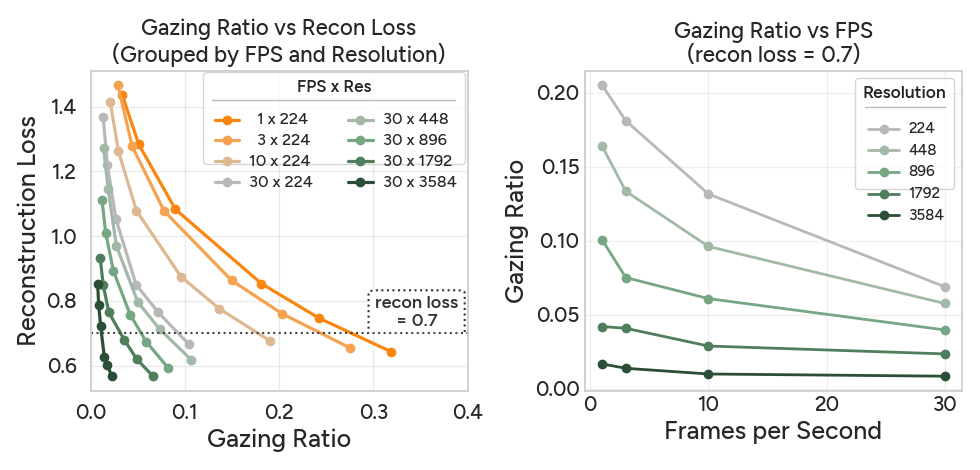
How many patches do we need?
There is a trade-off between gazing ratio and reconstruction loss: videos with higher FPS or resolution need lower gazing ratio to reach the same reconstruction quality.
We find that a reconstruction loss threshold of 0.7 usually leads to <0.5% performance drop while allowing videos to be represented with 4×-100× fewer patches.
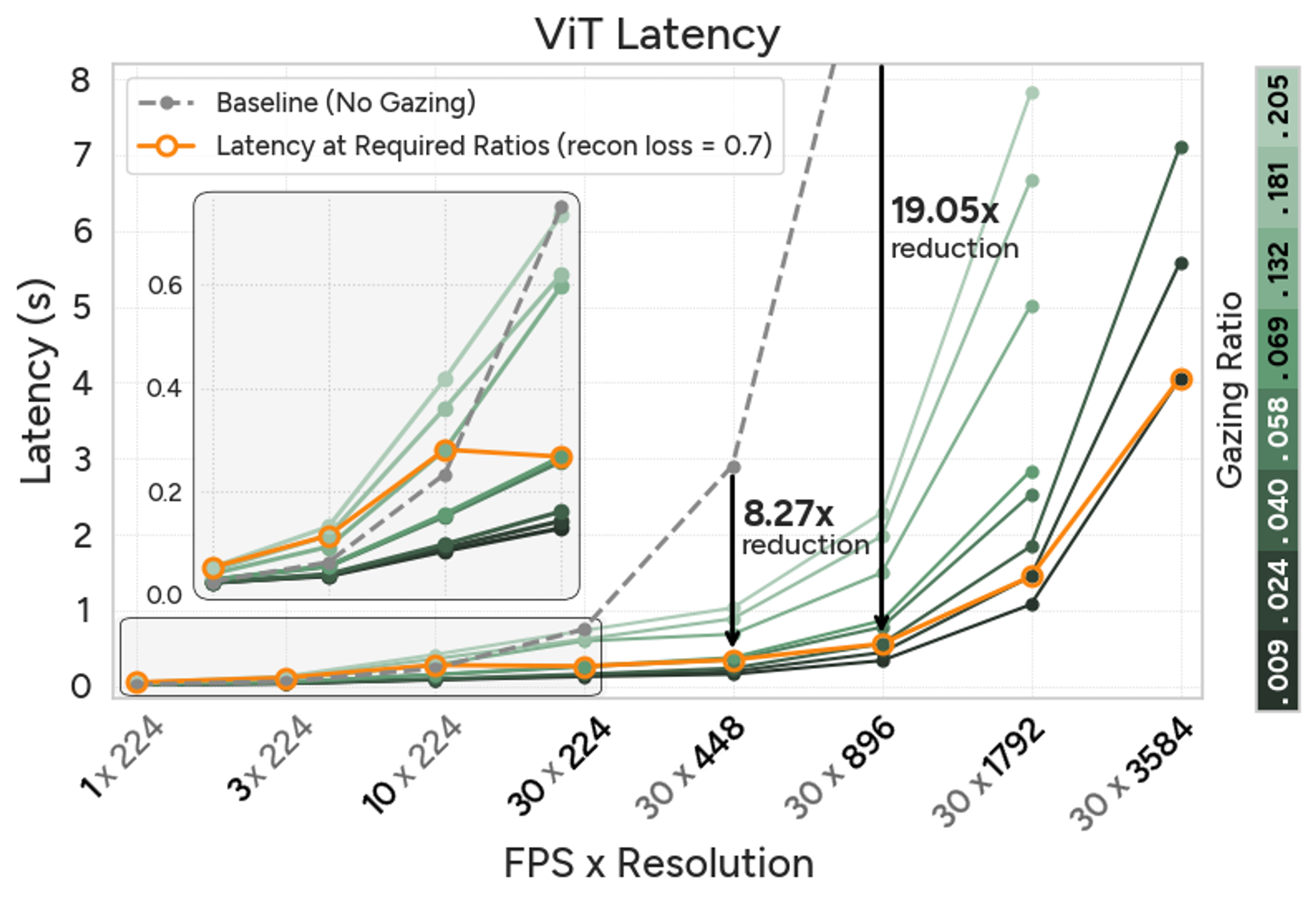
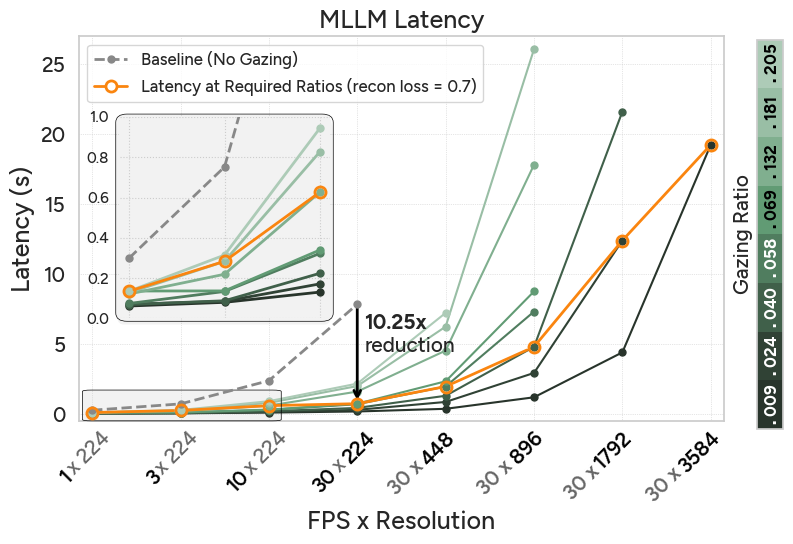
What speedups do we get?
When using the gazing ratio required for a reconstruction loss of 0.7, AutoGaze achieves up to 19× and 10× speedup for ViTs and MLLMs, enabling scaling to 4K resolution. Below, we show latency plots for one second of video with varying FPS and resolution.
HLVid: High-Resolution, Long-Form Video Benchmark
Although AutoGaze enables efficient understanding of long, high-resolution videos, benchmarks to evaluate this capability are still missing. We propose HLVid, the first long-form, high-resolution video QA benchmark featuring 300 QA pairs on 5-minute, 4K-resolution videos. Each question is manually reviewed to ensure high resolution and understanding throughout the entire video is required.
Check out and use HLVid on HuggingFace!
Performance on Video Benchmarks
We scale NVILA-8B to 1K-frame 4K-resolution videos, demonstrating consistent improvements on various benchmarks and outperforming strong MLLMs such as Qwen2.5-VL. See the paper for detailed quantitative results comparing with other MLLMs.
Citation
If you find AutoGaze useful for your research, please cite:
@misc{shi2026attendattentionefficientscalable,
title={Attend Before Attention: Efficient and Scalable Video Understanding via Autoregressive Gazing},
author={Baifeng Shi and Stephanie Fu and Long Lian and Hanrong Ye and David Eigen and Aaron Reite and Boyi Li and Jan Kautz and Song Han and David M. Chan and Pavlo Molchanov and Trevor Darrell and Hongxu Yin},
year={2026},
eprint={2603.12254},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2603.12254},
}